Bancolombia’s planned investment of COP 1.6 trillion (~USD 432 million) is a staggering figure. To put this in perspective, that budget could theoretically purchase some 450,000 top-of-the-line smartphones or nearly ten 1980s-era Cray X-MP supercomputers (see Cray X-MPs at current USD.) But as any systems architect knows, throwing hardware at a problem won’t fix a bottleneck governed by Amdahl’s Law.
Why do I specifically mention these brand and device models? First, I have been Bancolombia’s client for more than 40 years; Initially starting with a checking account at BIC and a savings account at CONAVI. Second, I used the Cray X-MP as my benchmark to represent the 40-year evolution of computing, even though my first interaction with a supercomputer was the Cray Y-MP, 37 years ago, which had been online for just a few weeks at the Pittsburgh Supercomputing Center (PSC). Third, I use the Samsung Exynos 2600 processor as current benchmark since it was commercially released recently on the Samsung Galaxy S26 smartphones line. Here are some comparisons to illustrate what has happened over the last 40 years:
| Feature | 1986 Benchmark (Cray X-MP) | 2026 Benchmark (Galaxy S26) |
| Processor Type | 4x Vector Processors[1] | Exynos 2600 10-core (1x Prime, 3x High-Performance, 6x Efficiency) |
| Typical RAM | 128 MB (16 million 64-bit words) | LPDDR5X (Up to 24 GB) |
| Peak Performance (GFLOPS) | ~800–942 MFLOPS (0.8–0.94 GFLOPS) | ~4,000+ GFLOPS (4 TFLOPS+) |
| Estimated Price (in current USD) | ~43,500,000 | ~954 |
| Power Consumption | 345 kW+ | Estimated < 5-10W |
By comparing these two extremes, we can visualize the sheer scale of the bank’s investment and why performance is no longer a matter of raw computing power, but of architectural efficiency. Therefore, I am contrasting Amdahl’s Law predictions against what the architectural solution must be.
I am initallyassuming that 2,000 Exynos 2600 processors could be put together in one or several computing clusters, making 20,000 processing elements (PE). Further, the acquisition cost (consumer price, USD954 apiece) of the S26 is what an organization would pay to set up a cluster, including hardware, software, and communications elements and licenses[2]. Assuming a 60% parallelization ratio (p = 0.60)[3], thus the combined capacity of those 2,000 such processors, working as a robust cluster, would be 12,000 transactions per second (TPS). Reportedly, on a typical peak day and hour Bancolombia currently processes up to 2,000 TPS, then with its planned investment over the next year, the bank will theoretically be able to meet the peak demand of TPS, with extra capacity to process unexpected peaks. Why theoretically? Because of Amdahl’s Law:
S: speedup
p: parallelizable fraction of a process, 0 ≤ p < 1. Conversely, s = 1 – p is the sequential part of a process that cannot be parallelized.
N: number of processing elements or cores
Notice, though, that the maximum speedup solely depends on s. Using the assumptions above, and plugging in, the calculation would be:
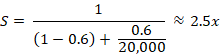
This means that the fraction is what really matters; the serial fraction is the bottleneck. Nonetheless, this speedup would be enough to process 2,000 * 2.5 = 5,000 TPS, which would provide a good margin to take care of the current peak demand of TPS. It is necessary to state that OLTP systems often scale via throughput[3]. Also, a conclusion from Amdahl’s Law is that to increase the speedup, processes (or rather, the algorithms running with them) must be optimized, increasing their parallelizable portion. Let us suppose that ideally, p is increased from 60% to 99%, then this is Amdahl’s Law prediction:
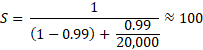
| Metric | Assumed Scenario (p=0.60) | Optimized Scenario (p=0.99) |
| Parallel Fraction (p) | 60% | 99% |
| Serial Fraction (s) | 40% | 1% |
| Max Speedup (S) | 2.5x | 100x |
| Theoretical Capacity | 5,000 TPS | 200,000 TPS |
| Bottleneck | Software/Logic Constrained | Hardware/Scale Constrained |
This result clearly proves that even with 20,000 cores, speedup is the fraction of 1/s or 1/0.01. Therefore, extra computing capacity does not bring speedup; but it may improve reliability, availability and serviceability (RAS)[4], provided new architecture is used, such as private or hybrid cloud computing and redundant data centers. Numerically, availability refers to the number of ‘nines’, representing the percentage of time that a system is running. The ideal 5-nines means 99.999% uptime. This article from Splunk Blogs describes the concept. Unanticipated outages, which reduce uptime, may have many causes, including events completely out of control of an organization. The cited Splunk blog lists some of them.
Let us revisit the recent Bancolombia outage. Initially, it was a scheduled stoppage, so it did not qualify as an outage affecting the availability index of the OLTP system. Once human error occurred, it transitioned into an unanticipated outage. Reportedly, the system took approximately 4 days to return to full operation. According to the table in Splunk’s article, this would place Bancolombia OLTP system between 99.25 and 99.5% availability.
How to increase availability ratios? Paraphrasing realtors, “redundancy, redundancy, redundancy”. This article by IBM shows that to increase a ‘nine’ means to reduce downtime by 10, i.e., it is an exponential progression with r = 0.1; so is the cost, with an r > 1. According to this other IBM’s article, in a case like Bancolombia’s, a starting point to increase “nines” would be to determine the worst acceptable scenario of downtime. In my opinion, Bancolombia needs at least 5-nines (99.999%) availability. To get it, Bancolombia would need redundant online servers (web, database, apps, storage, OS, …), redundant locations, redundant power supplies, redundant low latency communication elements and networks, all kept online so that at an outage of the production systems, the back-up systems are ready to take over.
Let us use again the example above with p = 60% and s = 40%. Furthermore, suppose that Bancolombia purposes to install a capacity of 5,000 TPS, to have room for growth. Since the attainable speedup is dependent on s, the necessary number of processing elements (PE) would be just around 600 per OLTP server-site; or
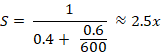
Namely, the fraction is what really matters; the serial fraction is the bottleneck. Nonetheless, this speedup would be enough to process 2,000 * 2.5 = 5,000 TPS, which would provide a good margin to process the current peak demand of TPS. It is necessary to state that OLTP systems often scale via throughput[5]. Also, a conclusion from Amdahl’s Law is that to increase the speedup, processes (or rather, the algorithms running with them) must be optimized, increasing their parallelizable portion. Let us suppose that ideally, p is increased from 60% to 99%, then this is Amdahl’s Law prediction:
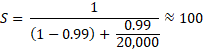
If 99.999% availability is the goal, then the OLTP servers must be redundant, i.e., an OLTP server-site could, itself, take care of the peak demand for processing. Namely, and by Amdahl’s Law, 20,000 cores would be equivalent to just 60 Exynos 2600 processors since adding more PEs after 600 would not increase speedup. Moreover, adding more hardware cannot overcome poorly optimized, non-parallel software. Hence, the total OLTP system must be at least 2 redundant online clusters, which have redundant everything. Thus, the cost of acquisition and installation of 120 Exynos 2600, set up as two clusters of 60 Exynos 2600, or 600 PE each, would be USD114,480, which is just 0.02% of the total project budget –see footnote 1–.
| Availability (“Nines”) | % Uptime | Annual Downtime | Infrastructure Requirement |
| 2 Nines | 99.00% | 3.65 Days | Single Server (No Redundancy) |
| 3 Nines | 99.90% | 8.77 Hours | Warm Standby / Basic Backup |
| 4 Nines | 99.99% | 52.6 Minutes | High Availability (HA) Clusters |
| 5 Nines | 99.999% | 5.26 Minutes | Full Multi-Site Redundancy |
Takeaway
- TThe increase in performance is limited by Amdahl’s Law, which establishes that speedup is limited by the serial fraction of a process (S = 1/s). Extra computing capacity does not bring speedup; it may improve RAS (reliability, availability, and serviceability), provided efficient architecture is set up.
- Most of the project budget will go to improving RAS, not to improving performance. Indeed, the assumptions made indicate that computing hardware would be just ~USD 114,480 (0.02% of budget). In other words, most of the COP 1.6 trillion is an investment in RAS. The bank is not paying for faster calculations; it is paying for the system to stay alive when things go wrong; these design features are sometimes referred to as ‘fault-tolerance’ and ‘resiliency’.
- The part of the budget destined for Infrastructure & Operations* is by far biggest: ~USD 432,317,952 (99.98% of budget)
* Includes: Data centers, low-latency fiber, power redundancy, cooling, licenses, and specialized engineering staff, in general, RAS improvement.
The conclusion is that computing power by itself is a small fraction of the total cost of the project. Most of the investment will go to operation costs and premises preparation and redundancies. I wish Bancolombia success in their endeavor.
[1] While the Cray brand name existed, its machines were mostly SIMD machines, appropriately called vector processors. Conversely, current processors, like the Exynos 2600 and Nvidia’s Grace and Vera CPUs, have multiple NPUs and GPUs, so computing clusters made up of current processors work as MIMD machines.
[2] In reality, there may be extra costs involved; for instance, use of server hardware, such as, AMD EPYC or Intel Xeon processors, ECC memories and NVMe storage arrays.
[3] A reason for this relatively low parallelism is that OLTP workloads are dominated by short, atomic transactions that require high data integrity, strict ACID compliance, and significant sequential locking, rather than large-scale parallel processing. In contrast, OLAP implementations typically have 95% or more parallel fractions. (Source: Google)
[4] Handling many independent serial tasks concurrently. It is worth noting that RDBMSs are the heart of OLTP. Thus, at peak times, an OLTP must process many transactions against the database. RDBMSs have mechanisms to manage concurrency (e.g., many users inquiring balances, withdrawing or transferring money at the same time), such as row-level locking, thus processing transactions in parallel.
[5] Reliability refers to a computer system operating well, as intended; availability, it operates reliably whenever it is necessary; and serviceability the computer system can undergo maintenance or updates, without affecting ‘R’ nor ‘A’.